
Quelle est la relation ?
Ces dernières années la loi de Moore s’essouffle alors que les usages continuent de progresser. Dans un blog très intéressant Tristan Nitot décrit ce lent processus. De plus le remplacement incessant des matériels informatiques a une empreinte carbone élevée sans parler du coût financier pour les entreprises et les particuliers. Remplacer un matériel qui n’est pas encore obsolète ou hors d’usage uniquement parce que les performances attendues ne sont pas au rendez-vous peut alourdir l’enveloppe budgétaire du projet.
La consommation électrique elle-même s’en ressent, faire tourner des processeurs à 80-90%, des accès disques incessants, uniquement parce qu’une structure de données est mal indexée, déplacer sans arrêt de gros volumes de données, tout n’est pas écologique non plus et aura tôt ou tard un impact sur la facture.
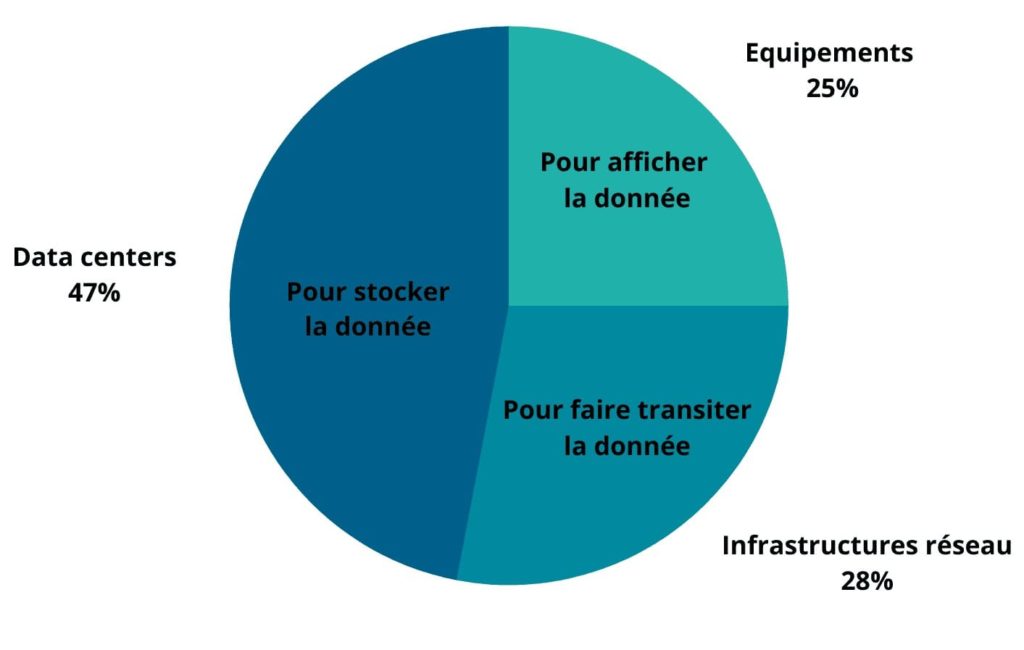
Et encore le graphique à droite n’est pas totalement complet. Globalement, l’ensemble des études s’accordent sur le fait que la plus grosse part de l’empreinte carbone du numérique réside dans la fabrication du matériel. Vient en deuxième la consommation électrique requise pour faire transiter, stocker et afficher la data (20%). Sur ces 20%, 47% des GES sont émis pour stocker la donnée, 28% pour faire transiter la donnée et 25% pour afficher la donnée.
Pourquoi optimiser ?
Déjà pour les utilisateurs : Une application peu réactive engendre de la frustration. Qui n’a pas été énervé par un wait cursor ou le fameux sablier Windows pour ceux qui l’on connu, par une application qui se fige plusieurs secondes alors qu’on est pressé d’enregistrer la commande dernière minute. Qui n’a pas pesté contre tous ces micro-retards accumulés au cours d’une journée. C’est encore plus pénalisant si cela ralentit vos lignes de production.

Qui ne s’est jamais posé la question : Je pourrais monter la cadence de production de la ligne mais derrière, vu les volumes d’échanges avec l’informatique, ça suit plus, il va falloir rajouter de la capacité mémoire, de la capacité de calcul, etc… Combien ça va encore me coûter pour gagner 2-3% de production horaire en plus ? Il va falloir encore changer tous les serveurs ?
Par où on commence ?

La première chose importante est de prendre du recul sur le définition de son projet. Faire un audit de ses ressources informatiques, l’infrastructure existante, et de modéliser une estimation de la charge supplémentaire qui va découler de la nouvelle application, du nouveau projet. En faisant cette modélisation, il faut bien prendre en compte les fonctionnalités existantes dans les autres applications, les autres briques logicielles. Certaines fonctionnalités feront peut-être doublon avec ce qui existe déjà. Puis-je récupérer des modèles de données qui sont déjà en place sur mes serveurs et les compléter au lieu d’aller monter un nouveau serveur de base de données de toutes pièces ?
Choisir ses données
Ce n’est pas parce que l’on a des tonnes d’informations que toutes sont forcément utiles maintenant, ou le seront dans le futur. La capacité de stockage a tellement augmenté ces dernières années que nombre d’entreprises sauvegardent des montages de données dont elles ne font absolument rien. Une donnée n’est utile que si elle représente une information pertinente dans la chaine de valeur de l’entreprise. Si elle n’est pas valorisée elle ne sert qu’à alourdir le système d’information. Un bon exemple est l’image du produit : Dois-je stocker toutes les images des produits qui sont contrôlés par inspection optique où seulement les produits défectueux ? En réalité très souvent seules les images comportant un défaut sont importante pour analyse et recherche de la cause de défaut. Allons même plus loin, l’image du produit présentant le défaut n’est pas forcement utile dans sa totalité seule la partie présentant le défaut est essentielle généralement.

Ne pas faire cet exercice peut rapidement conduire un système d’informations à ressembler à une immense décharge où les données moisissent en attendant des jours meilleurs tout en encombrant vos espaces de stockage.
Le matériel et le logiciel
Un de mes amis, Laurent GINESTE, fondateur de THE CREATIVE HIVE utilise le terme de « JUST TECH », c’est à dire juste ce qui est nécessaire, mais pas plus. En d’autres termes plus triviaux : A-t-on besoin d’un bazooka pour écraser une punaise ?
Ce concept vaut aussi bien pour le matériel que pour le logiciel ! Quand on comprend ça, on a déjà fait un énorme pas en avant vers les économies de carbone.
1. Coté matériel
Est-ce que j’ai besoin de rajouter des capteurs sur ma machine ? L’information (où les informations) que je souhaiterai utiliser ne sont déjà-telles pas présentes à quelque part ? Si oui comment les récupérer.
Est-ce que j’ai vraiment besoin de rajouter des serveurs ? N’ai-je déjà pas toute la capacité de stockage et de traitement dont j’ai besoin ?

2. Coté logiciel
N’ai-je déjà pas les applications nécessaires à ce que je souhaite faire ? Est-ce nécessaire d’acheter de nouvelles licences, d’investir dans une nouvelle application si ma pile logicielle est déjà capable de le faire. Puis-je faire évoluer un logiciel qui fonctionne déjà et l’enrichir de nouvelles fonctionnalités sans l’alourdir ?
Si c’est un nouveau développement, il faut considérer quelques points essentiels :
- Langage et environnement de développement
- Les frameworks nécessaires (et juste ceux-là)
- L’évolutivité et la maintenabilité
- L’empreinte mémoire et processeur,
- Le besoin de stockage
- Les déplacements de données (pertinence, rapidité)
Les frameworks, le no-code, le low-code
On utilise de plus en plus des frameworks, des ensembles de librairies, pour développer, se faciliter la tâche, essayer d’augmenter la productivité des développeurs. Ces frameworks s’ils répondent à des problématiques génériques, ne sont parfois pas totalement utiles, entrainent des dépendances parfois lourdes de conséquences sur la réactivité de tel ou tel processus d’une application. Un cas d’école est la fonction « is-string » sous Node.JS, cette simple fonction qui ne sert qu’à vérifier qu’une variable contient bien une chaine de caractères à recours à 14 autres bibliothèques Node.JS, alors qu’une simple ligne Javascript peut suffire :
const isString = (s) => typeof s === 'string'Il en est de même de nombreux frameworks qui injectent de nombreuses dépendances dans vos développements et dont la majeure partie ne sera pas utilisée et ne fera que rendre obèse une application qui du reste aurait pu rester très basique et légère.
Quand aux solutions low-code et no-code, ces dernières ne sont conçues que pour des applications génériques (et parfois très basiques) et sont rarement très optimisées en terme de code généré derrière. De plus dès que l’on doit sortir de ce qui est prévu, des blocs de programmation fonctionnels proposés, ça devient vite compliqué et on est obligé de « tordre le bras » au produit pour arriver à faire certaines choses qui seraient évidentes avec un langage de programmation plus traditionnel.
J’appelle ceci du développement « pré-mâché », en aucune manière une façon efficace et rentable sur le long terme de mener un projet.
Coder proprement
Si vous développez ou faites développer votre outil, attachez-vous à la propreté du codage. En effet un code propre est toujours plus maintenable et optimisable qu’un code abscons et confus et cette règle est valable pour tous les langages. Si par exemple, vous voyez un simple fonction de détection de sens passage qui contient 1500 lignes de code c’est que vos développeurs n’ont pas compris ce qu’ils doivent faire où ne savent pas le faire correctement.
/* Que fait ce programme ? */
#include <stdio.h>
int main(void)
{
int zkmlpf,geikgh,wdxaj;
scanf("%u",&zkmlpf);for (wdxaj=0,
geikgh=0;
((wdxaj+=++geikgh),geikgh)<zkmlpf;);
printf("%u",wdxaj); return 0;
}
Bon c’est un exemple tiré par les cheveux, mais on est parfois confronté à bien pire.
Un autre principe que j’aime à défendre est le principe KISS : Keep-It Simple, Stupid. En gros faire le court et le plus simple possible, découper autant que possible une fonctionnalité complexe en actions élémentaires faciles à coder et à optimiser. Pour résumer, quand on doit optimiser, il est plus facile de déplacer plusieurs petites briques qu’un gros rocher de plusieurs tonnes.
The last, but not the least
Surtout toujours avoir le but du projet en tête et rester dans le cadre de ce qui a été défini au départ. Bien avoir conscience que si des demandes d’évolutivité peuvent faire sens, celles-ci pourront toujours êtres intégrées après coup, seules les évolutions légères et non-intrusives devraient être considérées dans la phase de développement ou de déploiement. Ceci est particulièrement important car j’ai vu trop de projets partir dans tous les sens et devenir des usines à gaz inutilisables.
Conclusion
En ayant en tête ces quelques règles simples, l’optimisation rendra service à la planète mais préservera aussi vos budgets informatiques, vos ressources financières et augmentera la satisfaction de vos collaborateurs qui seront amenés à utiliser le produit dans leur travail au jour le jour. Le ROI de vos projets sera aussi significativement impacté de façon positive.


Sources
(1) Le blog de Tristan Nitot : https://blog.octo.com/la-loi-de-moore-est-morte-et-c%27est-une-bonne-nouvelle
(2) HelloCarbo : https://www.hellocarbo.com/blog/reduire/empreinte-carbone-numerique/
(3) Blog LinuxFr.org : https://linuxfr.org/news/deno-2-0-est-la
Laisser un commentaire